PDF 번역를 처음 검색한 사람이 바로 따라 할 수 있도록 공식 기능 기준, 실제 사용 순서, 실패하기 쉬운 지점을 함께 정리했습니다.
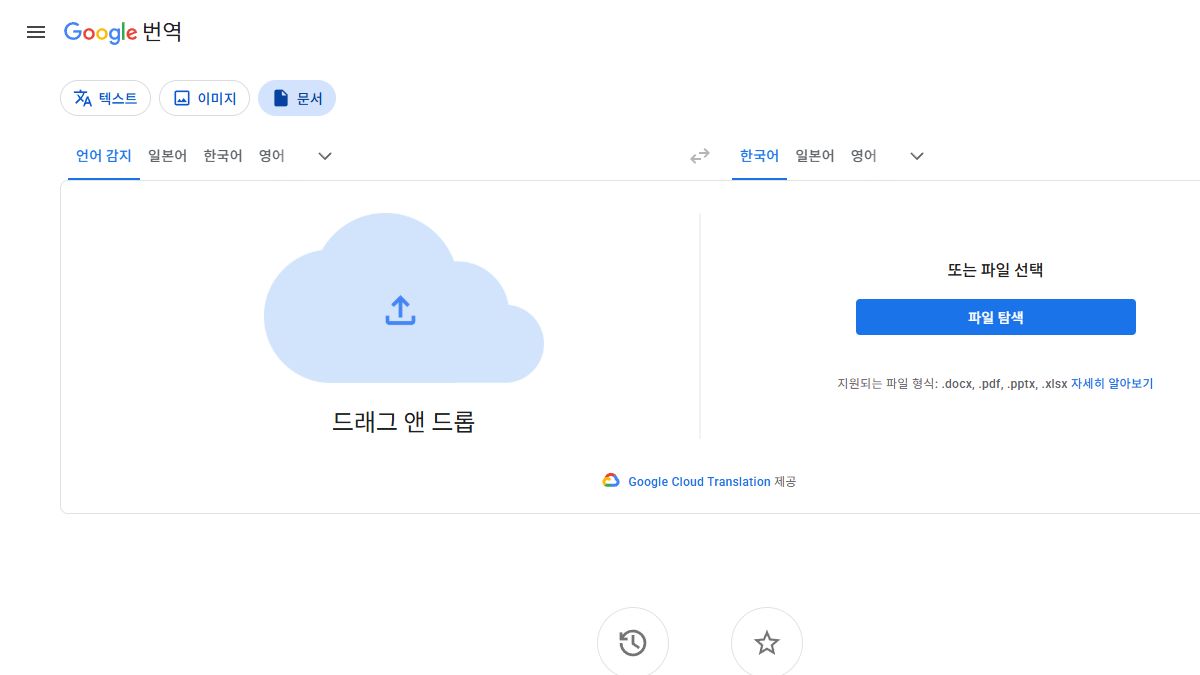
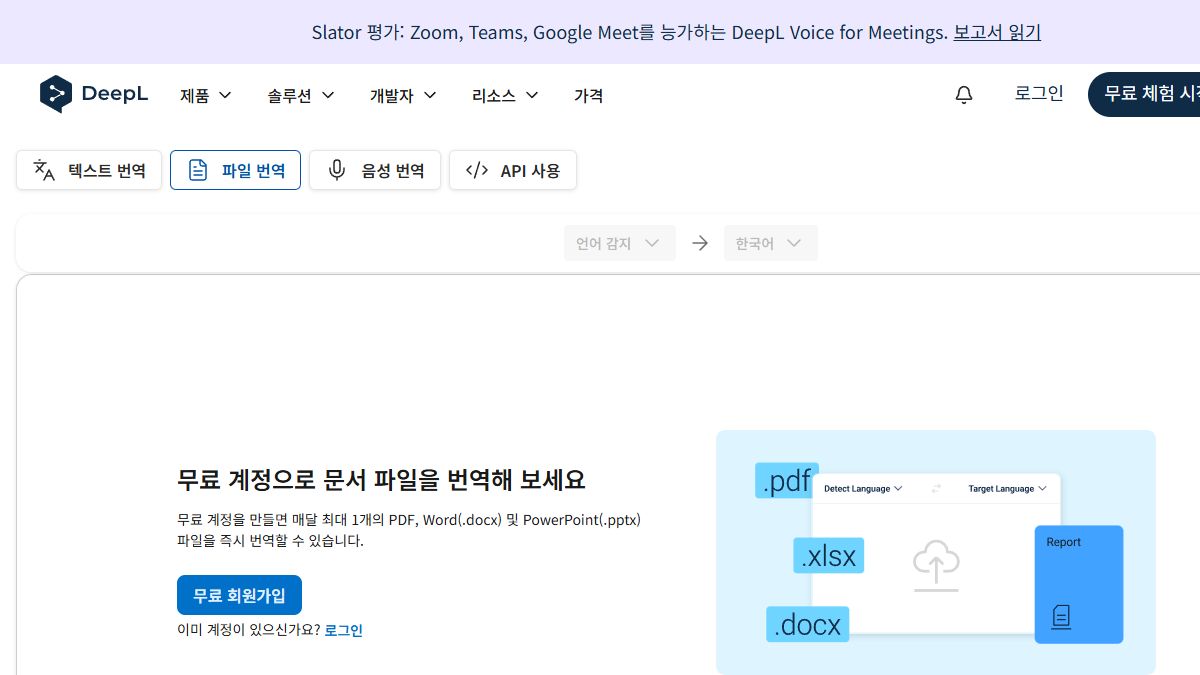
PDF 번역은 도구보다 문서 상태가 먼저입니다
PDF 번역을 검색하면 여러 서비스가 나오지만, 실제 결과 차이는 번역 엔진보다 원본 PDF의 상태에서 먼저 갈립니다. 텍스트를 선택할 수 있는 PDF는 Google 번역이나 DeepL에 바로 넣어도 결과가 비교적 안정적입니다. 반대로 스캔본처럼 이미지로 된 PDF는 먼저 OCR로 텍스트를 추출해야 하며, 표가 많은 보고서나 계약서는 번역 후 서식이 틀어지는지 반드시 확인해야 합니다.
초보자라면 “한 번에 완벽한 번역본 만들기”보다 “내용 파악용 번역”과 “제출용 문서”를 나눠 생각하는 편이 안전합니다. 내용 파악용은 Google 번역 문서 탭처럼 빠른 도구가 편하고, 자연스러운 문장 검수는 DeepL 파일 번역이나 문단 단위 교정이 유리합니다.
PDF 번역 추천 순서
마우스로 문장을 드래그해 복사할 수 있으면 일반 문서형 PDF입니다. 복사가 되지 않으면 스캔본일 가능성이 높습니다.
파일을 올리고 대상 언어를 고른 뒤 전체 흐름을 빠르게 봅니다. 제목, 표, 각주가 어떻게 처리되는지 체크합니다.
보고서, 제안서, 논문 초록처럼 문장 자연스러움이 중요한 문서는 두 결과를 나란히 보고 어색한 문장만 골라 고칩니다.
금액, 날짜, 단위, 제품명, 조항 번호는 자동 번역보다 원문 확인이 우선입니다.
주민번호, 계약 금액, 내부 자료가 들어간 PDF는 공개형 번역 서비스에 올리기 전에 보안 정책을 확인해야 합니다.
Google 번역과 DeepL을 나눠 쓰는 기준
| 상황 | 먼저 쓸 도구 | 이유 |
|---|---|---|
| 외국어 PDF를 빠르게 훑어보기 | Google 번역 문서 탭 | 접근이 쉽고 전체 문서 흐름을 빠르게 확인하기 좋습니다. |
| 문장 자연스러움이 중요한 문서 | DeepL 파일 번역 | 문단 단위 표현을 다듬을 때 비교 기준으로 쓰기 좋습니다. |
| 스캔본 PDF | OCR 후 번역 | 이미지 상태의 글자는 번역 전에 텍스트 추출이 필요합니다. |
| 계약서·공식 제출 문서 | 자동 번역 후 사람 검수 | 법적 의미가 바뀌면 안 되므로 최종 검수는 분리해야 합니다. |
실수하기 쉬운 부분
PDF 번역에서 가장 흔한 실수는 번역 결과만 보고 숫자와 고유명사를 확인하지 않는 것입니다. 특히 “may”, “shall”, “must” 같은 표현은 문맥에 따라 의무와 가능성이 달라질 수 있습니다. 또 표 안의 줄바꿈이 깨지면 원문과 번역문이 한 칸씩 밀리는 경우가 있어, 제품 스펙이나 가격표는 반드시 원본과 나란히 비교해야 합니다.
공식 레퍼런스
기능 사용 가능 여부와 파일 제한은 서비스 정책에 따라 바뀔 수 있습니다. 실제 작업 전에는 Google 번역 문서 탭, DeepL 파일 번역, Google 번역 도움말을 확인하세요.
함께 보면 좋은 글
자주 묻는 질문
PDF 번역 결과가 이상할 때 가장 먼저 확인할 것은 무엇인가요?
원본 PDF가 텍스트형인지 스캔본인지 먼저 확인해야 합니다. 스캔본은 OCR 품질이 낮으면 어떤 번역기를 써도 문장이 흔들릴 수 있습니다.
무료 PDF 번역만으로 업무 문서를 제출해도 되나요?
내용 파악에는 충분할 수 있지만 제출용 문서는 숫자, 고유명사, 조항, 단위를 원문과 대조해야 합니다.
Google 번역과 DeepL 중 하나만 써야 하나요?
아니요. 빠른 전체 이해는 Google 번역, 문장 자연스러움 검수는 DeepL처럼 역할을 나누면 결과가 더 안정적입니다.